Molecular Notes: Practice
In this Part 2, I discuss the practical implementation of Molecular Notes in Obsidian. I explain how I organise my Second Brain (Tags, Folders, Topics) and present detailed workflows for ingesting different types of content. I also explain how one can extend Obsidian, giving the example of Polymer – a spaced repetition application that I built on top of my Second Brain.
After reading this post, if you would like to clone my setup, head over to the Molecular Notes GitHub repository and follow the instructions!
Contents
- Choosing software
- Organising my Second Brain
- Learning from different sources
- Synthesis
- Hacking Obsidian
- Areas of improvement
Choosing software
I split the post into Part 1 and Part 2 (this post) to emphasise the difference between philosophy and implementation. Molecular Notes (as a note-taking philosophy) is not tied to any particular software tool. The only non-negotiable constraint is strong support for bidirectional links – when you link from note A to note B, note B should be aware that it has just been linked to.
Depending on your workflows, you may have other requirements for an app. For me, some other minimum requirements are:
- Flexibility: because I’ve spent a lot of time thinking about how I want to take notes, I need a system that allows me to structure notes how I see fit. Flexibility may not be desirable for everyone! Constraints can help you think in a structured way and avoid “blank page syndrome”.
- Speed: when making notes, I jump around a lot to explore connections (this is encouraged by Molecular Notes). I need a tool that doesn’t slow me down, otherwise I’ll get fed up.
- Support for mathematical notation since many of my notes contain formulae.
- Graph view: a convenient visual representation of a Second Brain.
- Sparks joy! This is completely subjective – I want a tool whose interface gels with me. In my case, this means something lightweight and hackable.
I use Obsidian, which nails all of these requirements and offers many other great features. Obsidian is built for linked notes and is naturally suited to Second Brains. It is hackable, offering deep customisation and flexibility. Since it is essentially just a wrapper around simple text files, I don’t have to worry about being “locked-in” to Obsidian (in fact, I often interact with my notes from other apps). Obsidian works perfectly well offline, while still providing benefits like cloud-syncing.
That said, I can completely understand that Obsidian may not be the right app for everyone. It has the same vibe as a programming environment / IDE, which is great for me, but perhaps annoying for non-programmers. In the rest of this section, I briefly comment on several other options for software (I’ve tried most of them). For readers who are already sold on Obsidian, feel free to skip ahead.
Notion
I have written extensively about Notion elsewhere. I once used Notion to implement Zettelkasten – my first iteration of a Second Brain inspired by Sonke Ahrens’ How to Take Smart Notes (my highlights here).
Notion is an extremely powerful tool – it’s certainly possible to implement Molecular Notes in Notion and I know several people who happily use it for their Second Brain. I am a heavy user of Notion for PKM (personal knowledge management), but I moved my Second Brain away from Notion for several reasons:
- Notion is a swiss-army knife, not a precision tool. It offers a tonne of functionality but does each thing less well than a pure-play app. For example, Notion’s Kanban boards are great but probably not as good as Trello’s. Likewise, unlike Obsidian, Notion is clearly not designed specifically for linked note-taking.
- Following on from the above, there are many nice-to-have Second Brain features like graph view that are absent from Notion. This is not Notion’s fault; it is a general-purpose PKM tool, not a Second Brain tool!
- Historically Notion has had pretty poor offline support – a constant reminder that all of your notes are stored on Notion’s servers!
- Slow: Notion feels slow for Second Brains. For example, if you start trying to create a backlink using “[[some note“, there is a noticeable delay before that note pops up. In Obsidian, it feels instantaneous.
RemNote
RemNote is a note-taking app that treats spaced-repetition as a first-class citizen, while also providing strong support for bidirectional linking. I used RemNote religiously during university and the spaced-repetition functionality was a game-changer – it allowed me to memorise content in the most efficient way possible.
The main reason why I shifted to Obsidian for my Second Brain is that Obsidian is more hackable and extensible. With RemNote, there’s not much you can do to customise the interface and all the notes are stored on RemNote’s servers. Additionally, for my Second Brain, spaced repetition (at least in the way RemNote does it) isn’t terribly important.
Roam Research
Roam has a credible claim to being the app that sparked the renaissance in Second Brains. It is heavily optimised for linked thinking and would be a great app for Molecular Notes.
My main criticisms:
- It is not as flexible as Obsidian and feels a bit more prescriptive. For example, in Roam, every note consists of bullet points.
- It is primarily web-based. I think this makes it harder to have a clean and focused note-taking experience. (EDIT: there is now a desktop app, which possibly nullifies this point).
- All the notes are files on Roam’s servers.
- There is no free plan. I have no qualms with paying for something as valuable as a Second Brain, but there are many excellent free options out there.
That said, there are several great things about Roam:
- Arguably because it’s paid, you can have more faith that the company will stay around for a while and implement new features (though Obsidian’s team has proven to be highly capable in that respect).
- Excellent graph view.
- Links to blocks rather than just to notes. In Molecular Notes, this doesn’t matter much, but for other systems it’s very useful to be able to link to specific paragraphs.
- Unlinked references: Roam probably beats Obsidian on this particular point – with one click you can turn all unlinked references into proper backlinks.
VSCode
VSCode is an IDE (integrated development environment) that I use for most of my software development. I often use VSCode to interact with my Obsidian notes (e.g. when I want to do special find-and-replace operations across the entire database).
However, it turns out that there are VSCode extensions (like Foam and Dendron) that essentially turn VSCode into an Obsidian clone. I use Dendron at work because I don’t have access to Obsidian behind the company firewall.
These apps are quite similar to Obsidian but the UX is slightly less polished because of the IDE’s constraints. The learning curve was a lot steeper since the target audience for these apps are software developers (not many “normies” have VSCode installed!). Unless you are obsessed with VSCode (not unreasonable!), I think Obsidian offers a better note-taking experience.
OneNote/Evernote
Avoid! The difficulty of linking internal notes means that these apps cannot be used as effective Second Brains. I don’t think they even support bi-directional links!
Evernote was the first note-taking app I used (from 2015-2019), so I did have some sentimental attachment to it. But ultimately they failed to innovate and were left in the dust by competitors like Notion (there are many great articles on the failure of Evernote).
OneNote is actually rather good for general note-taking but not for Second Brains. Microsoft seems to be aware of this and is launching a product called Loop, which looks like a Notion clone and should therefore work as a Second Brain (presumably with all the problems of Notion).
Summary – Choosing Software
Broke: Notion
Woke: Roam
Bespoke: Obsidian
Baroque: Evernote/OneNote
All told, you need to pick a note-taking app that gels with your philosophy. The core tenets outlined on Obsidian’s website are exactly what I want:
- Linked thinking as the primary objective
- Lightweight and extensible
- Local markdown notes
Organising my Second Brain
People who have tried to get started with note-taking (either digitally or with pen and paper) will quickly appreciate the pain of “organisation paralysis”: it can be hard to decide how to use tags, folders, categories etc, and you often end up with a convoluted system that is impossible to maintain.
As I argued in Part 1, this doesn’t mean that we should avoid categorisation! It just means that we should focus on a simple and flexible structure.
Tags
I use tags to encode the type of a note. That is, a tag should represent “is-a” relationships: this note “is-a” book note, this “is a” Molecule etc.
Here is a list of my most commonly used tags:
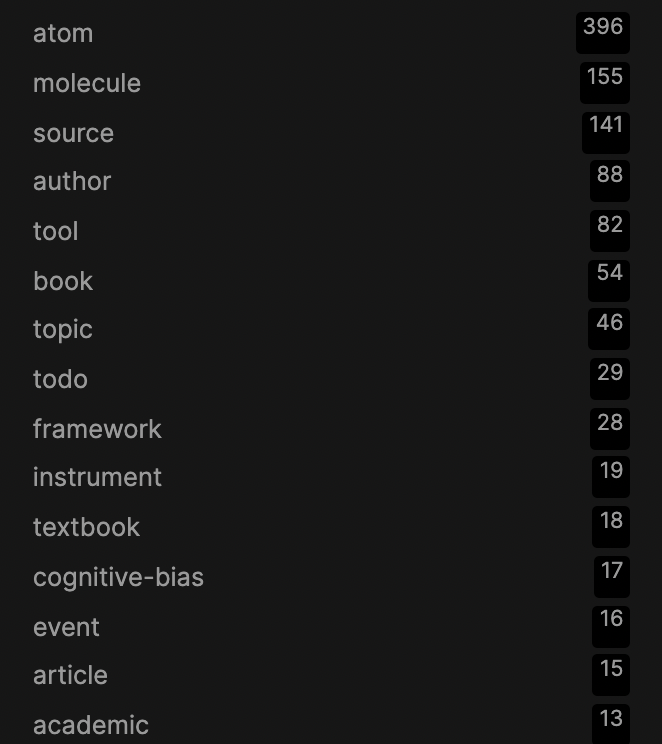
Obviously, we have the main Molecular Notes primitives: Atom, Molecule, Topic, and Sources (please refer back to Part 1 for a refresher).
All of my Source notes have an additional tag denoting what type of Source it is, e.g. a book or an article. Most of my Atoms have an additional tag denoting the type of Atom, for example it could be a tool, historical event, formula, etc. In the list above you may be surprised to see “cognitive-bias” as a tag – arguably this should be a Topic instead. But so many of my Atoms are cognitive biases that I think it is a suitable tag. I bring this up to remind the reader that “practicality beats purity” – feel free to modify the system to suit your needs!
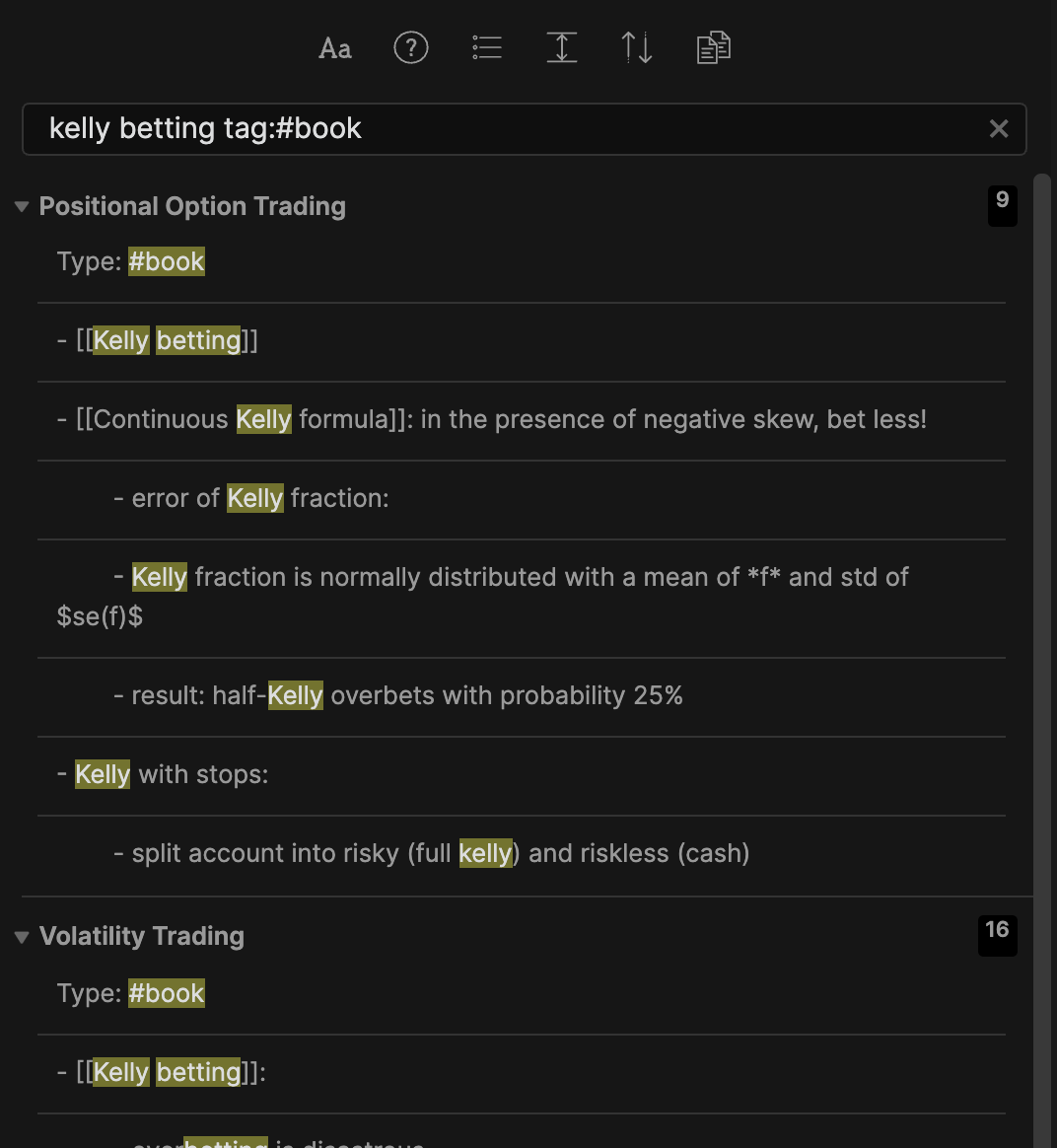
Tags make it very easy to search through notes. For example, I can quickly find all books that mention Kelly Betting using ⌘⇧F.
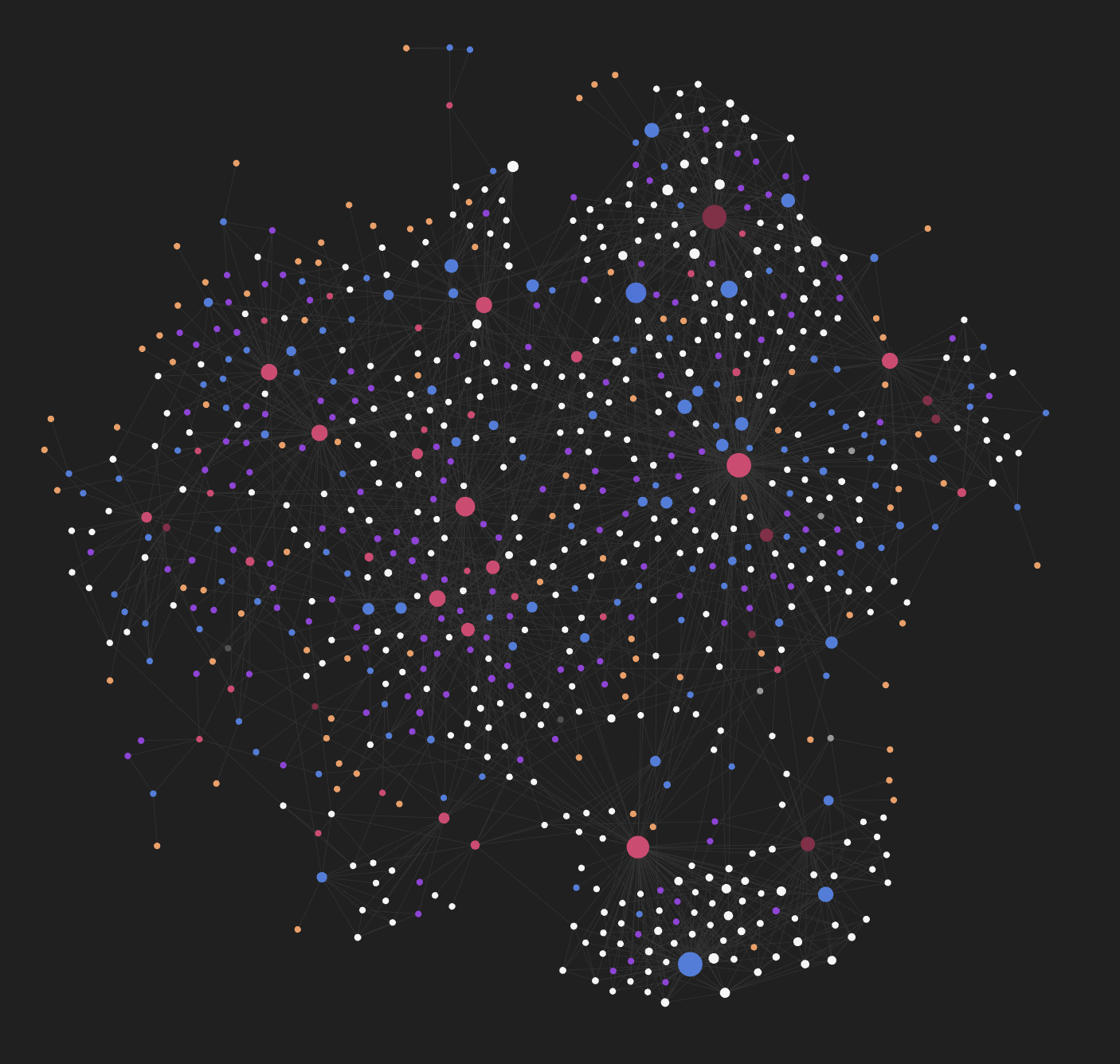
Additionally, Obsidian has a cool feature that allows you to colour graph nodes by tag:
Folders
Within my main Obsidian vault, I use a simple folder structure (there is no further nesting):
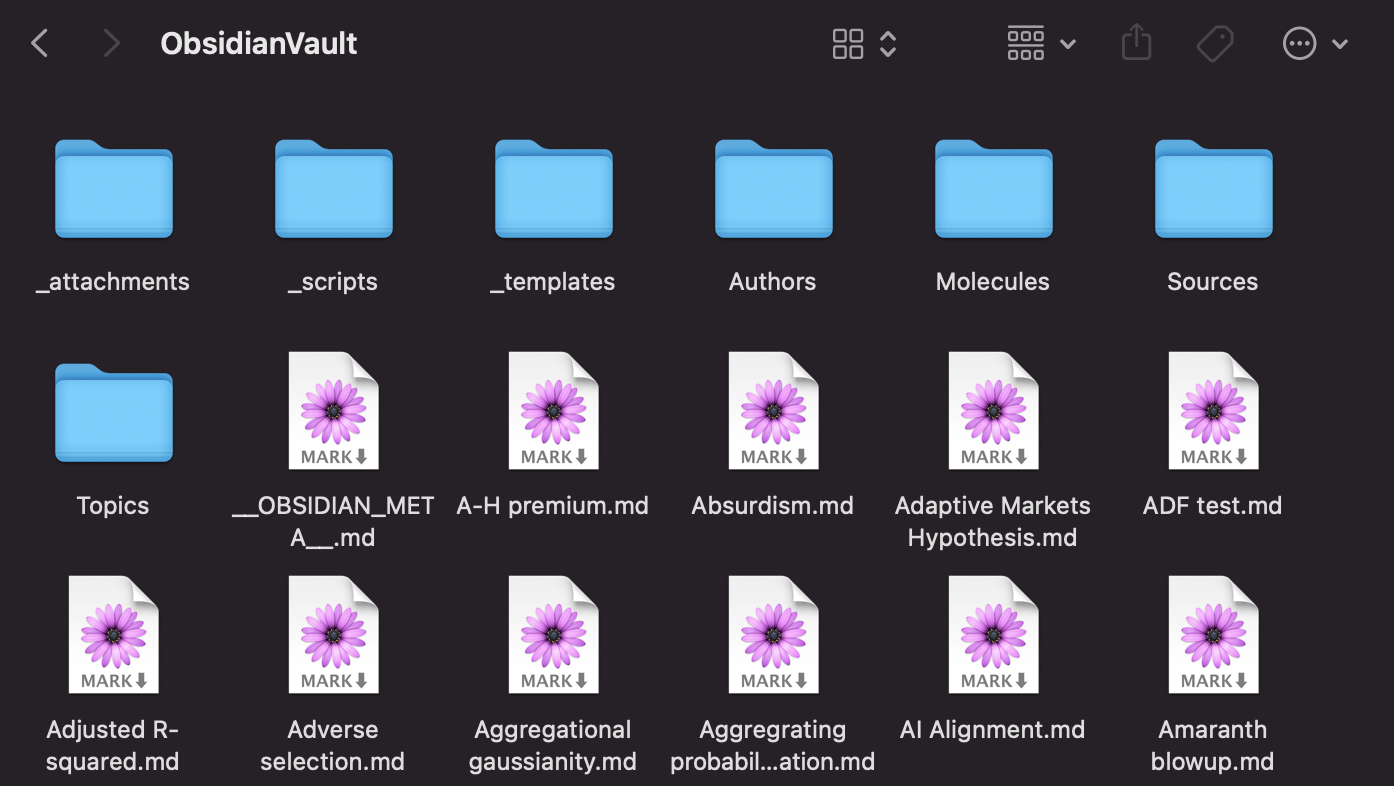
The folders with an underscore in front of them are “system” folders that are used by Obsidian – they don’t contain my notes.
All Atoms go in the main Obsidian vault, not in subfolders. This decision was based on the observation that opening Atoms is probably the action I do most often, so I should reduce the number of clicks as much as possible.
I use folders to house specific types of notes: Authors, Molecules, Sources, and Topics. A reasonable question: doesn’t this create duplication between folders and tags? Why bother creating a folder where everything inside it is tagged a certain way? The answer is that folders speed up navigation; they are great for “skimming” your Second Brain. For example, I often want to skim through a list of my Molecules. While I could do this using a search for “tag:#molecule”, this is such a common task that it’s more efficient to be able to simply click “Molecules” in Obsidian’s file explorer and be able to quickly look through:

The downside of this approach is that I have to remember to move a new note to the correct folder. I wrote a python script to do this for me (i.e. move all notes tagged “#molecule” to the Molecules folder), but even without that, it can be done quickly using the command palette (⌘P “move” ⏎) or you can set a custom shortcut.
Topics
Topics are the main “semantic” source of structure (tags and folders are more organisational). They are a powerful tool in helping me to identify connections across domains:

I don’t have a set procedure to decide when something should be given an explicit Topic. As a very rough rule of thumb, I make something a Topic if I think more than ~5-10 notes will link to it. Some of my most-used Topics are Finance, Statistics, Philosophy, Volatility (in the financial sense), and Management (notes related to running businesses).
Volatility is an interesting example because it is actually a Subtopic of Finance, in the sense that any note related to the Volatility Topic should also be related to the Finance Topic conceptually. But in these cases, I will only link to the Subtopic. Hence if I am writing a new Atom about volatility (e.g. some new options concept), even though it is indeed related to Finance, given that it is only related to Finance via its relation to Volatility, I will only link it to the Volatility Subtopic. This results in a clearer graph structure.
Don’t worry too much about deciding the best Topics. I often restructure and rename the Topics – this iterative procedure helps me remain abreast of the contents of my Second Brain.
Authors
At the top of all my Source notes, I write down the author. But rather than doing this as plain text, I make an empty Author note (containing only Type: #author) and link to that.
The advantages of this approach are threefold:
- The Authors show up on the graph.
- Because the Authors are notes tagged
#author, I can give them a different colour on the graph. -
If I ever need to note down information about the author, I can easily do so on the Author page.

However, these advantages only materialise when there are several Sources from the same Author in your Second Brain (or you reference the Author in Atoms/Molecules). If this is unlikely to be the case, e.g. if I’ve read a one-off blog post from some random author, I will leave the author as plain text.
One downside of making placeholder Author notes is that one ends up having to create a lot of notes which then need to be filed away into folders (at least according to my organisation principles). I have written a python script that does this all for me – all I have to do is make an unlinked reference e.g. author: [[Firstname Lastname]] then my helper script will create a Firstname Lastname.md note and move it to Authors/.
Learning from different sources
As I explained in Part 1, a key goal of Molecular Notes is to help me learn from a variety of resources: books, textbooks, podcasts, YouTube videos etc. In this section, I explain how I make Source notes for different media types.
Before that, let me review some key principles:
- Avoid duplication:
- If two Sources are explaining the same concept, that concept should be extracted into an Atom and linked to by both Sources.
- But if each Source provides different commentary on the same concept, I can and should make a note of both.
- Before making notes on a Source, I first pull up similar Sources so I can get a better grip on what’s already in my Second Brain. Often, I end up restructuring my old notes at the same time as making new notes!
- Review-oriented structure:
- Notes should be hard to write but easy to review – put in the effort to rearrange things until the structure makes sense!
- I’m a big fan of using nested bullets because they let me look at my content on different levels of abstraction, allowing for efficient review. When I’m looking over my Source notes later, I can scan the headings and the top-level bullets to find what I’m looking for (or maybe I’m just browsing), before diving into a particular point in more detail if needed.
- Contrast this with a paragraph of text, where I essentially have to read the whole paragraph to figure out what the paragraph is discussing. Converting textbook prose to nested bullets isn’t always easy, but having to re-arrange concepts helps me internalise the material.
- Naming conventions:
- I’m not at all consistent with how I name Source notes – sometimes I use the original title, sometimes I append the author e.g.
Complexity, Mitchell. For journal articles, I will either use the title or the reference, e.g.Avellaneda and Stoikov (2008). - How do I decide? I name the note whatever I would like to reference it as. This is my Second Brain, so I let the note name reflect whatever symbol I have in my mind.
- I generally avoid abbreviations because the marginal effort of linking a long name is tiny due to autocomplete. Again, there are some exceptions to this – if the abbreviation is strongly embedded in my mind (e.g.
GEBforGodel, Escher, Bach: an Eternal Golden Braid), I will just use the acronym!
- I’m not at all consistent with how I name Source notes – sometimes I use the original title, sometimes I append the author e.g.
Books
I have discussed at length how I consume books in a previous post. For completeness, here is a summary:
- My book review and highlights are contained in Notion (they can be viewed here).
- I then copy the key highlights into a Source note.
- I extract “known” concepts into Atoms and crystallised pieces of insight into Molecules.
- I look through other notes from the same Topic (using the local graph) to find potential connections.
Textbooks and online courses
As discussed in Part 1, Sources are composed of concepts, context, and a thesis. The key distinction between books and textbooks (one can find/replace “textbook” with “online course” in this section since the principles are identical) is that textbooks focus far more on concepts and facts, whereas non-fiction books contain a core thesis and supporting examples. Thus I expect a textbook to result in far more Atoms than a non-fiction book.
Here are some guidelines when making notes on textbooks:
- Consume the content in at least two passes:
- I normally read over a textbook (or watch lecture videos) once on 2x speed just to get an idea of what ideas it contains, before making proper notes on a second pass.
- This helps me have a sense of what’s important – or indeed if the textbook is worth reading!
- Mimic structure:
- I generally follow the structure of the textbook because it makes it much easier to refer back to the original textbook when I need additional details.
- Obsidian lets you link to headings, so in other notes, I could refer to Volatility Trading Chapter 2 with a proper backlink (see the Obsidian docs for an explanation)
-
But one must be careful not to fall into the trap of completionism: just because we are following the textbook’s structure does not mean that we need to take detailed notes on every chapter! I sometimes leave chapters as just a heading if the ideas aren’t immediately relevant to me.

- Utility over comprehensiveness:
- We don’t need to re-explain everything in the book! In fact, we should think of Source notes as a collection of pointers. The note should just tell you what is in the Source.
- Unless you expect a concept or idea to be particularly important for your thinking (in which case you should extract it into an Atom or Molecule), feel free to write nothing more than a minimal phrase to remind you of its existence.
Probably the most differentiated aspect of my textbook workflow (compared to typical textbook note-taking) is that only 70% of the time spent making textbook notes is spent on that particular textbook. The other 30% is spent extracting relevant Atoms from other textbooks. For example, I was recently making notes on Ben Lambert’s excellent course on undergraduate econometrics. I had previously read a textbook called Forecasting – Principles and Practice that had a lot of overlap, especially on the subject of time series. So I kept this open in the right pane, and whenever there was a concept that was discussed both by Lambert and Forecasting, I would extract it into an Atom.
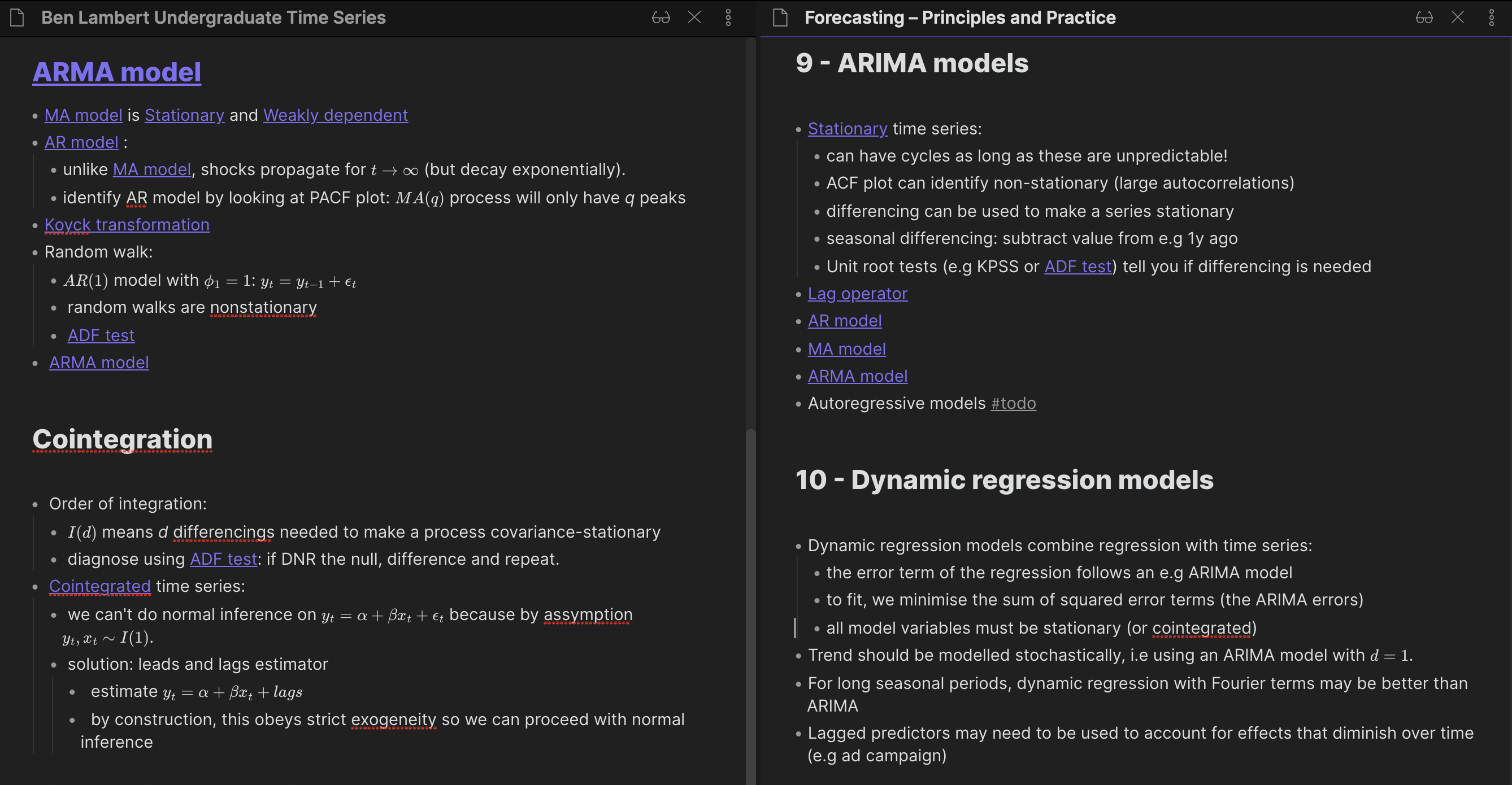
With reference to the above image, previously my Source notes in Chapter 9 – ARIMA models looked quite similar to Chapter 10 – Dynamic regression models: lots of text with few links. But as I was making notes on Lambert’s course, I progressively extracted Atoms like “AR model”, “MA model”, “ARMA model” – though note that there is still some Source-specific commentary under in Chapter 9 – ARIMA models, like that within the “Stationary time series” bullet.
This process leaves me with a far better understanding of the concepts because I have to:
- View the same concept in different contexts
- Merge two explanations for the same concept
- Reconcile different notation to strike at the underlying idea
Information media
I generalise blog posts, YouTube videos, Twitter threads etc to “information media” (infomedia).
The main difference between these types of infomedia and books/textbooks is that they typically focus on a much narrower range of concepts – often just one!
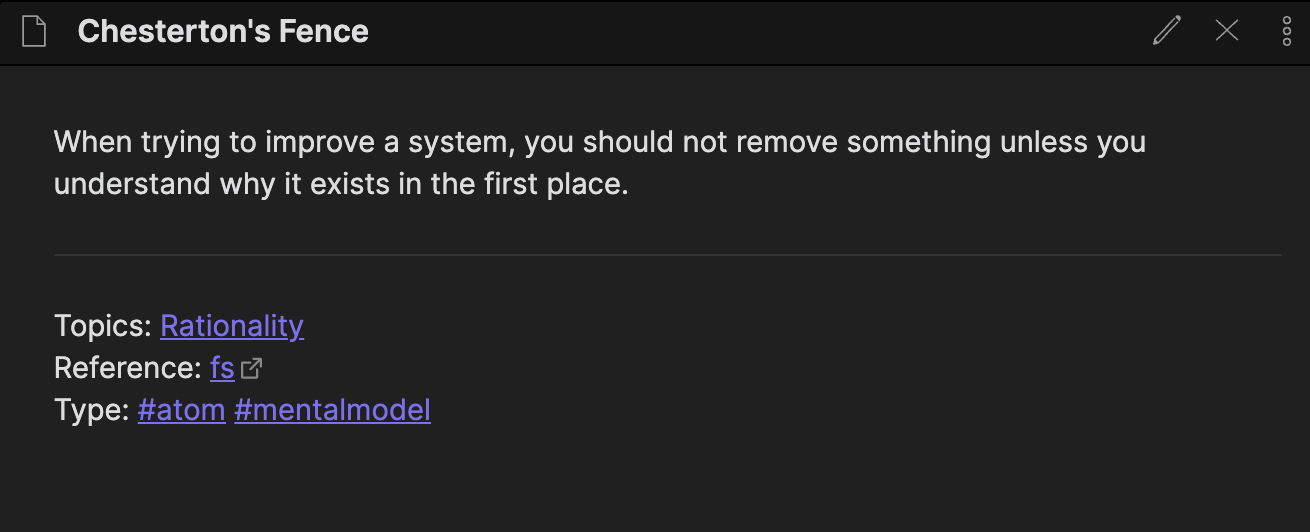
In these cases, I will often directly create an Atom to explain the concept (in my own words of course) then link to the infomedia directly (not to a Source note of it). In the example below, I read a Farnam Street post about Chesterton’s fence and made an Atom for it. I didn’t create a Source note for the blog post.
Podcasts
Podcasts have been an incredibly important learning vector for me. They are an excellent way to add incremental learning to my day – as a rule of thumb, I listen to podcasts any time my body is in use but my brain is not: when I’m at the gym, walking from A to B during a commute, cooking and cleaning, etc.
There are several types of podcasts, each of which I treat differently (a list of the podcasts I consume can be found here).
- General news and current affairs (e.g. All-In): I don’t make notes on these – I listen to them in the gym and they are primarily for entertainment.
- General interviews, e.g. Invest Like the Best, Masters in Business: I occasionally take notes if there is an insight that strongly resonates with me.
- Evergreen interviews, e.g. Flirting With Models: these are podcasts that have been carefully designed to be dense in evergreen information. I make notes on these as if they are online courses (i.e textbook-equivalent).
- “Long-form”, e.g. the History of Rome, Huberman Lab: as above, I treat these as online courses.
I use an app called Airr that allows me to make audio highlights; when I hear something interesting, I press a button to record an AirrQuote and if convenient I make a text note (these are optional).
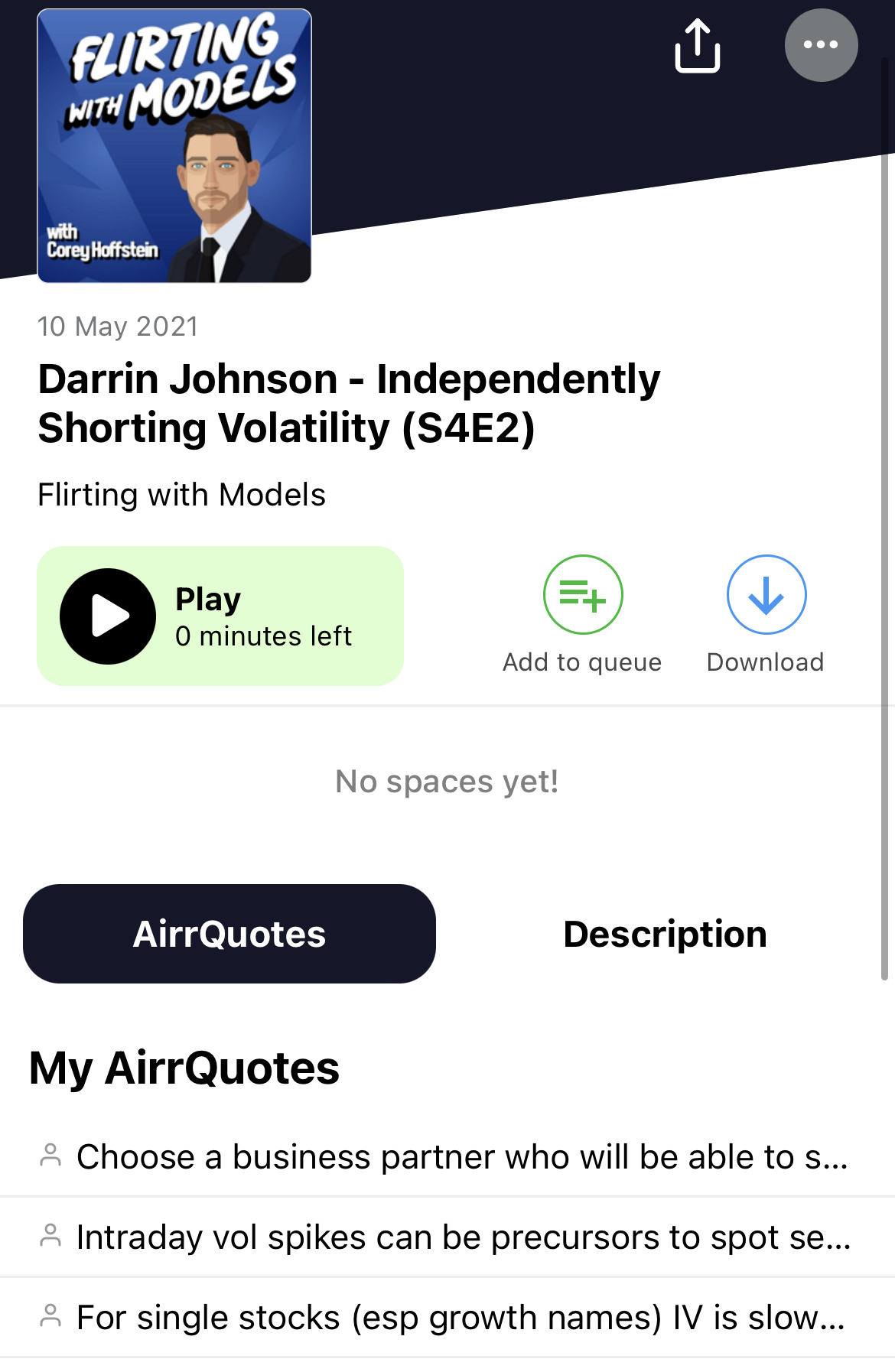
At certain intervals (e.g. every few episodes, or every season if I’ve gotten lazy) I compile all the highlights into Source notes – either one note per podcast or one note per podcast season depending on the information density.
Journal articles
I first want to caveat by saying that I am not an academic, so my workflow for journal articles is primarily from the perspective of a “keen amateur” – I generally care more about learning techniques from the articles, as opposed to citing and building on top of them.
My Source notes for journal articles are most similar to my Source notes for books: they are often very short, highlighting just the key ideas that are relevant to my thinking.
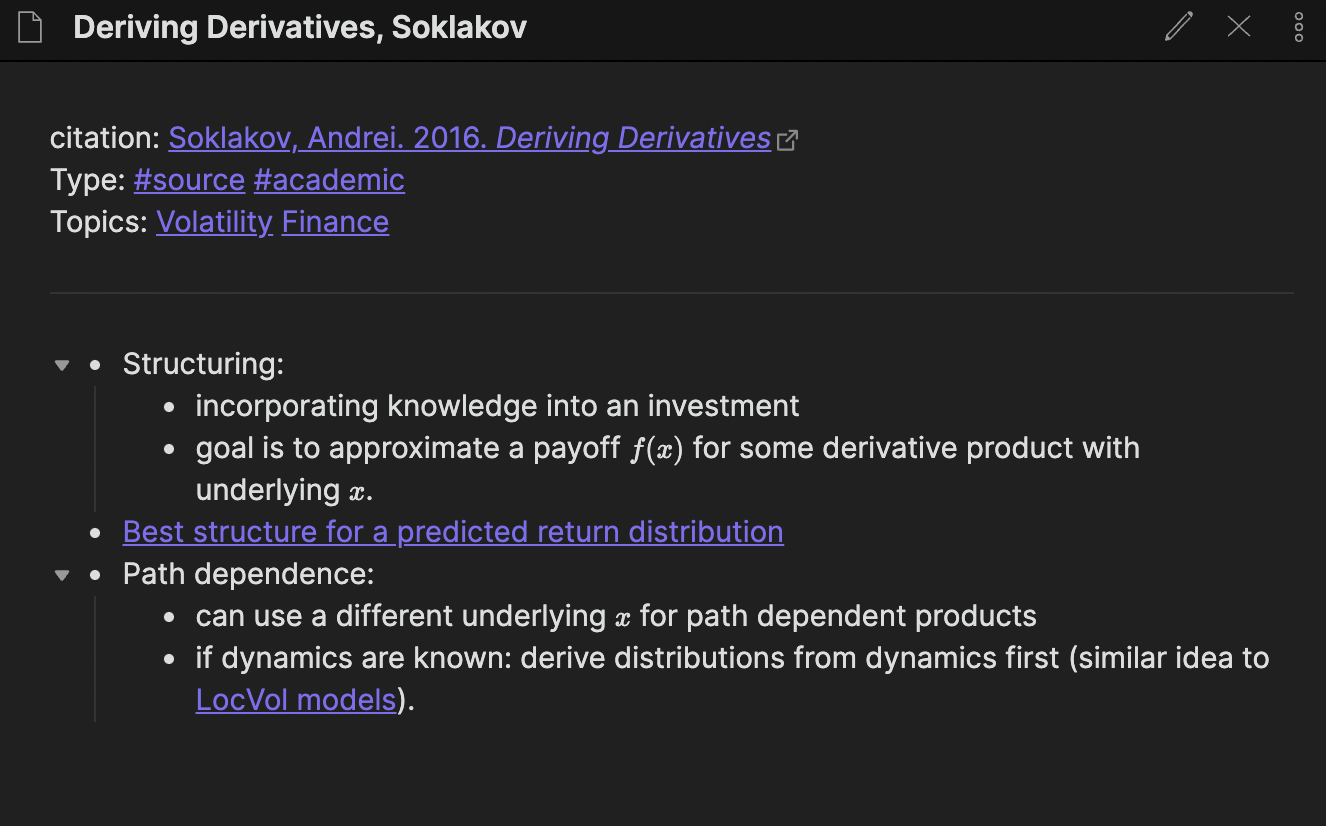
I name the note whatever feels right – sometimes that’s the formal citation, sometimes it’s the name of the paper (if it’s particularly memorable). In the front matter for the note, I give the formal citation as a link to Zotero, which I use to store and arrange the PDFs of the papers.
Synthesis
Synthesis is one of the important parts of a Second Brain, but it is also the aspect I am least able to convey in a blog post. While I’ve built a system that aids synthesis, the truth is that it’s a process that must occur in one’s (primary) brain.
My approach isn’t to sit down and say “right, it’s time to be creative”. Most often, the process starts while I’m making notes on a particular Source: perhaps the author discusses a concept that feels vaguely familiar or has a similar flavour to something I’ve come across before. I then gently poke around my Second Brain to try and see if there’s a deeper link.
The local graph is useful here because I have configured it to show both first-degree and second-degree neighbours. The second-degree neighbours are often a fertile hunting ground for connections. In the example below, the “Goal preservation” Atom links to the AI Topic. The local graph shows not just the neighbours of “Goal preservation”, but the neighbours of “AI” too. I can then skim these to see if there are additional links to “Goal preservation”
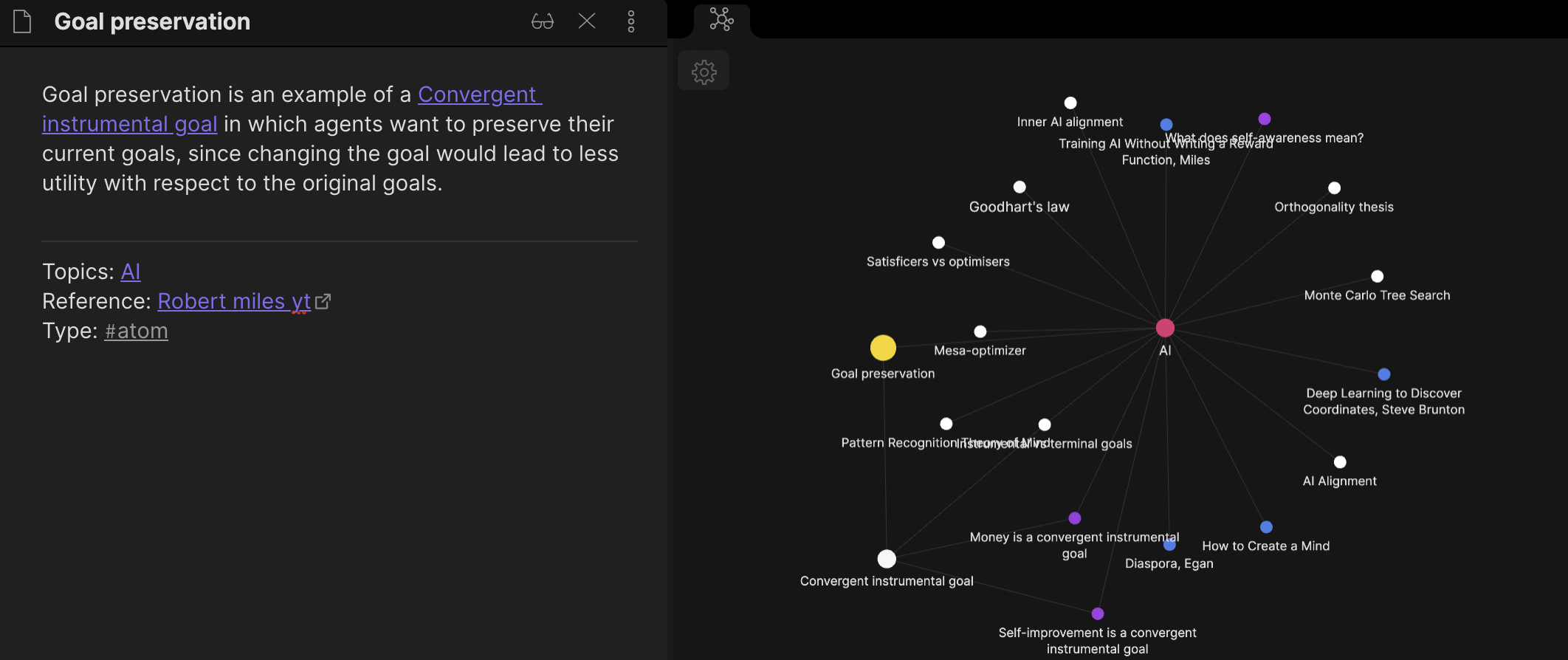
Occasionally, I do put on my “linking cap” – I set aside some time to go through my Second Brain to remind myself what’s in there and to specifically try and make connections between Atoms via new Molecules.
Hacking Obsidian
In this section, I discuss how one can “hack” Obsidian. This section is entirely optional; it is mainly here for the benefit of the advanced users and geeks (you know who you are!) who want to push the boundaries of Obsidian.
In essence, because Obsidian is made of plain markdown files and a simple folder structure all stored locally, it’s very easy to interact with your Obsidian notes via a different interface. Here are some examples.
Third-party extensions
There are a tonne of third-party extensions available for Obsidian which require very little effort to set up. For example, the Mind Map extension lets you view your notes as a mindmap (provided you have structured them properly, using nested bullets):
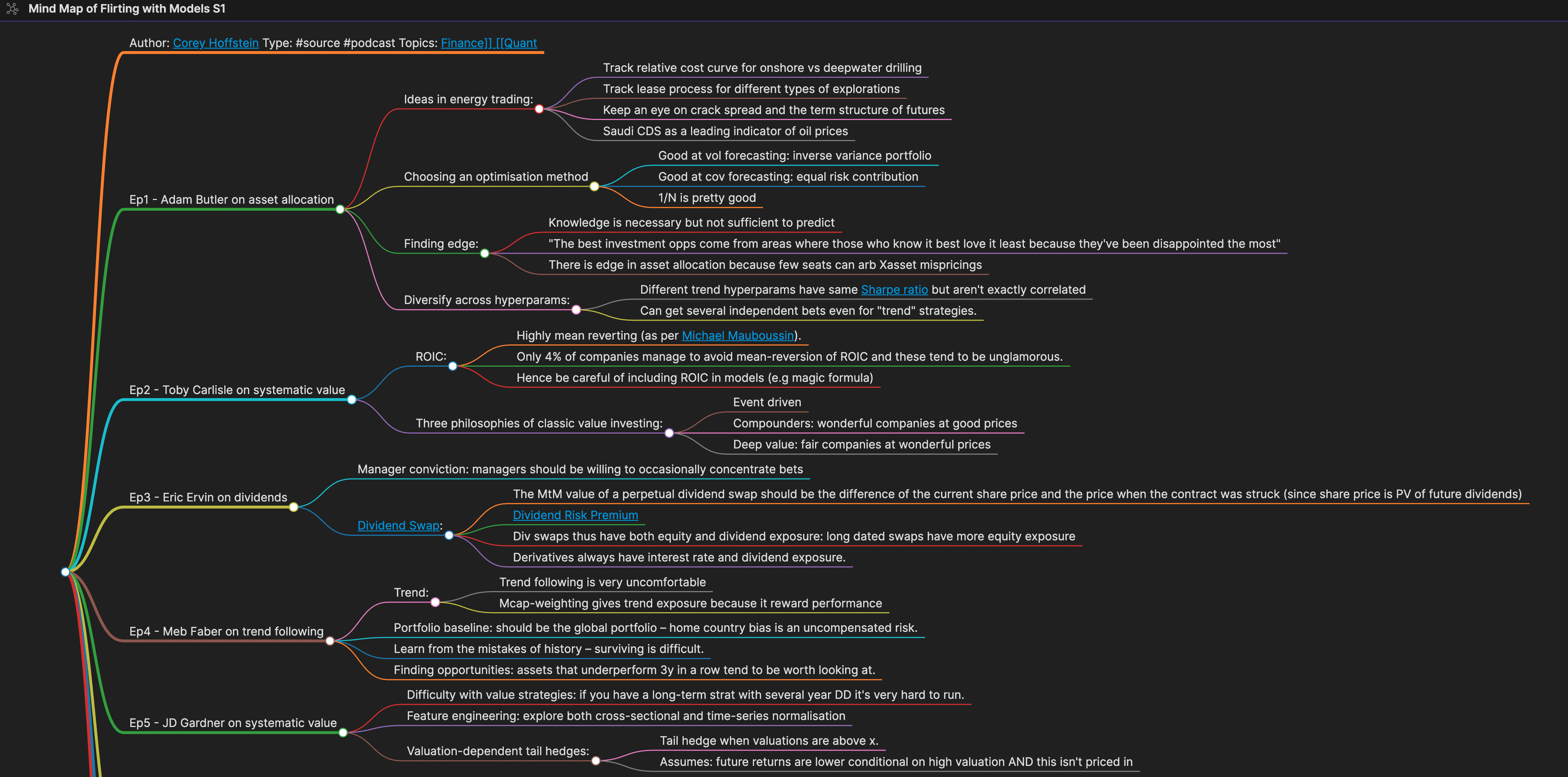
Viewing notes from a text editor
Notes are just plain text in folders, which means you can interact with them via your file system. For example, on macOS, this means that your Obsidian notes show up in Spotlight search, which can be quite useful. It also means that you can reorganise your notes in Finder or File Explorer.
Slightly more advanced: I often interact with my Obsidian vault via VSCode, a programming environment.
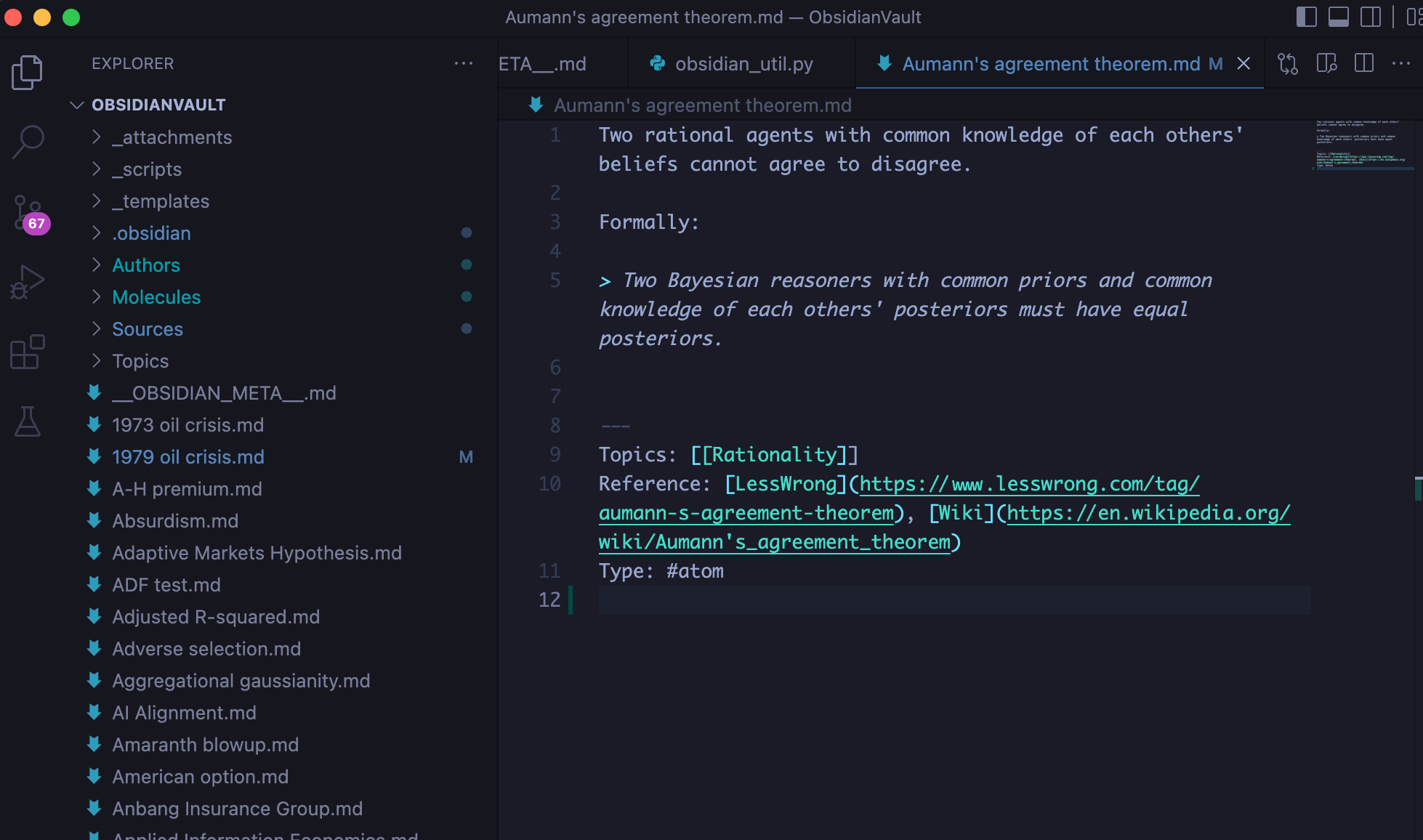
Backlinks don’t work here, but there are several reasons why this is useful:
- You can use VSCode’s powerful text editing functionality. For instance, in Obsidian there isn’t an easy way to do a global find and replace across all notes, but this is trivial in VSCode (plus you can do regex find/replace rather than just plaintext).
- Better support for git backups. Obsidian does have a git extension, but in VSCode you can look at diffs and see exactly what is being changed.
- More convenient to write python scripts that interact with my Second Brain (see below).
Python helper script
As I’ve mentioned several times in this post, there are a couple of “routine tasks” that I’ve decided to automate using python. My helper script does the following:
- Moves files with a given tag into the appropriate folder (e.g. Authors, Molecules, Sources)
- Creates Author pages: if I’m making a new Source note and write
author: [[New Author]], it doesn’t actually create a page for the author (unless I click on the backlink). My script looks through these linked-but-not-created pages and makes an Author page (empty apart fromtype: #author). - Creates Topic pages: same as for Authors.
- Makes a list of notes that I need to review:
- Notes that I’ve tagged
#todo. - Orphan notes that aren’t linked to by anything and don’t link to anything.
- Notes that I’ve tagged
I then set up an alias where if I run obsidian in terminal, it cleans up my library and gives me a report:
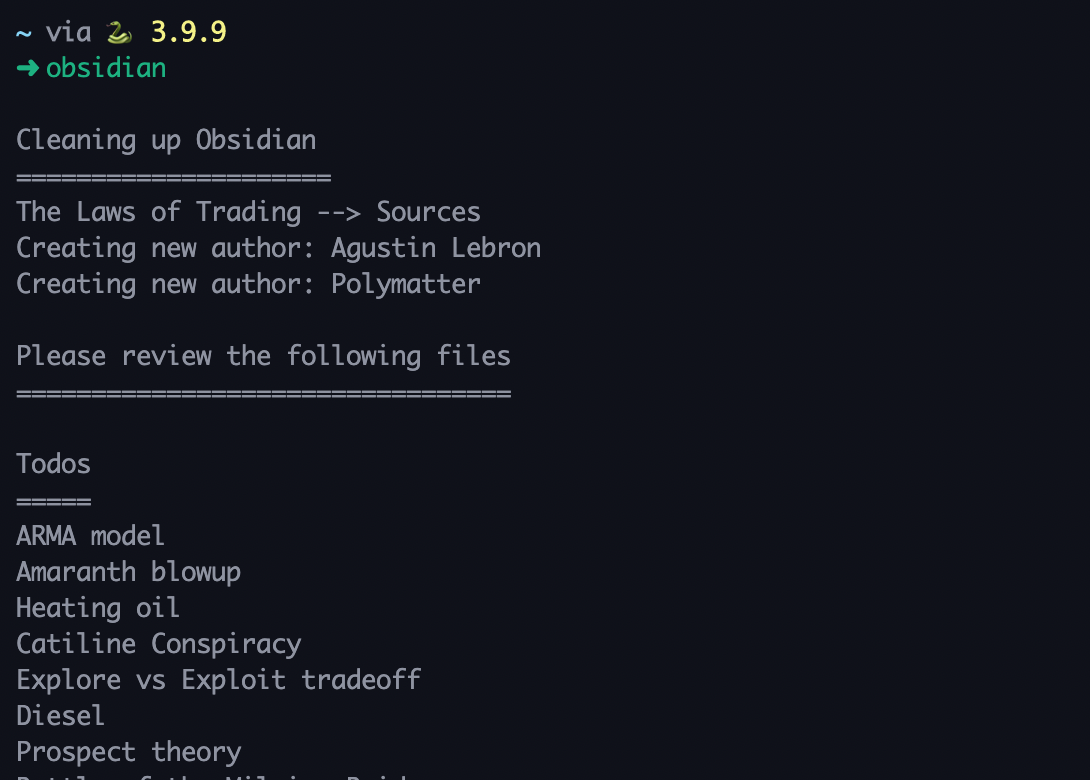
The code to do all this is remarkably simple – check out the Molecular Notes GitHub repo.
Polymer
One can also build more advanced applications. I built a spaced repetition (flashcard) tool called Polymer to help me review my notes in a different way.
Like other flashcard tools, Polymer flashes the title of an Atom or Molecule and I try to recall the contents. I then press “Show” to check my understanding, before clicking one of the Difficulty buttons to tell Polymer how hard I found it to recall the note. It then uses a dumb spaced repetition algorithm (explained below) to decide when it should next show me the note.
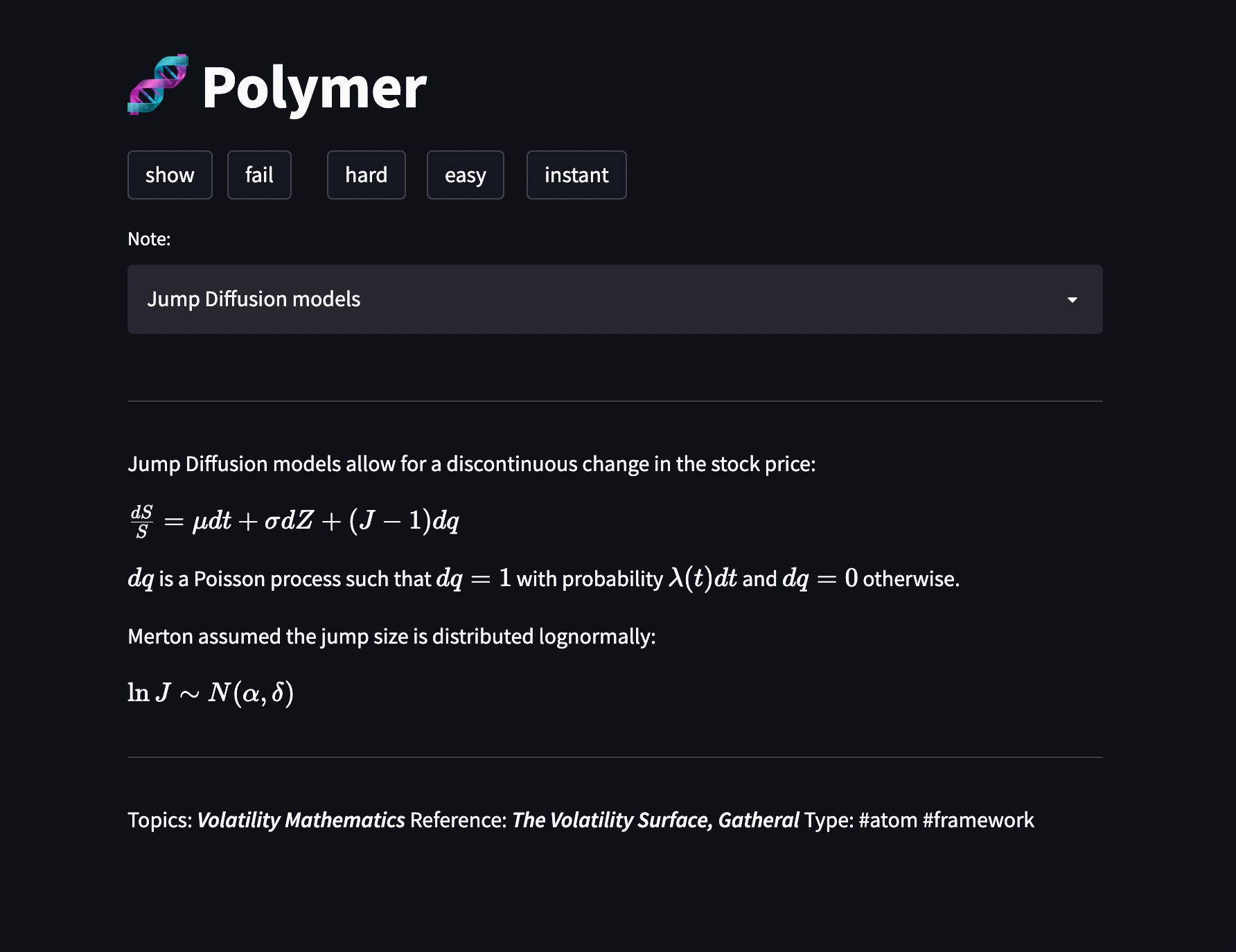
At a high level, the tool is structured as follows:
- Streamlit dashboard as a frontend.
- A simple JSON “database” to track my stats for different notes: when I last reviewed it, what my recall level was, etc.
- A very dumb spaced repetition algorithm to construct a queue from the database: if I “fail” to recall the note, it gets pushed back 10 places in the queue; if I recall the note with difficulty, the note gets pushed back 20 places in the queue etc.
Areas of improvement
As we reach the end of the post, I want to briefly discuss some areas where I am currently improving my workflows.
Maps of Content
I currently don’t have good entry points into most of my Topics. For example, if I want to refresh myself on concepts related to Management, I tend to wander around the local graph.
In future, I would like to have better indexing via “Maps of Contents” (MOCs). A MOC is simply a semi-structured way to explore a particular Topic. Rather than leaving the Topic note empty, I should use it to organise notes. Here is an example of a MOC I have for the Volatility Topic.
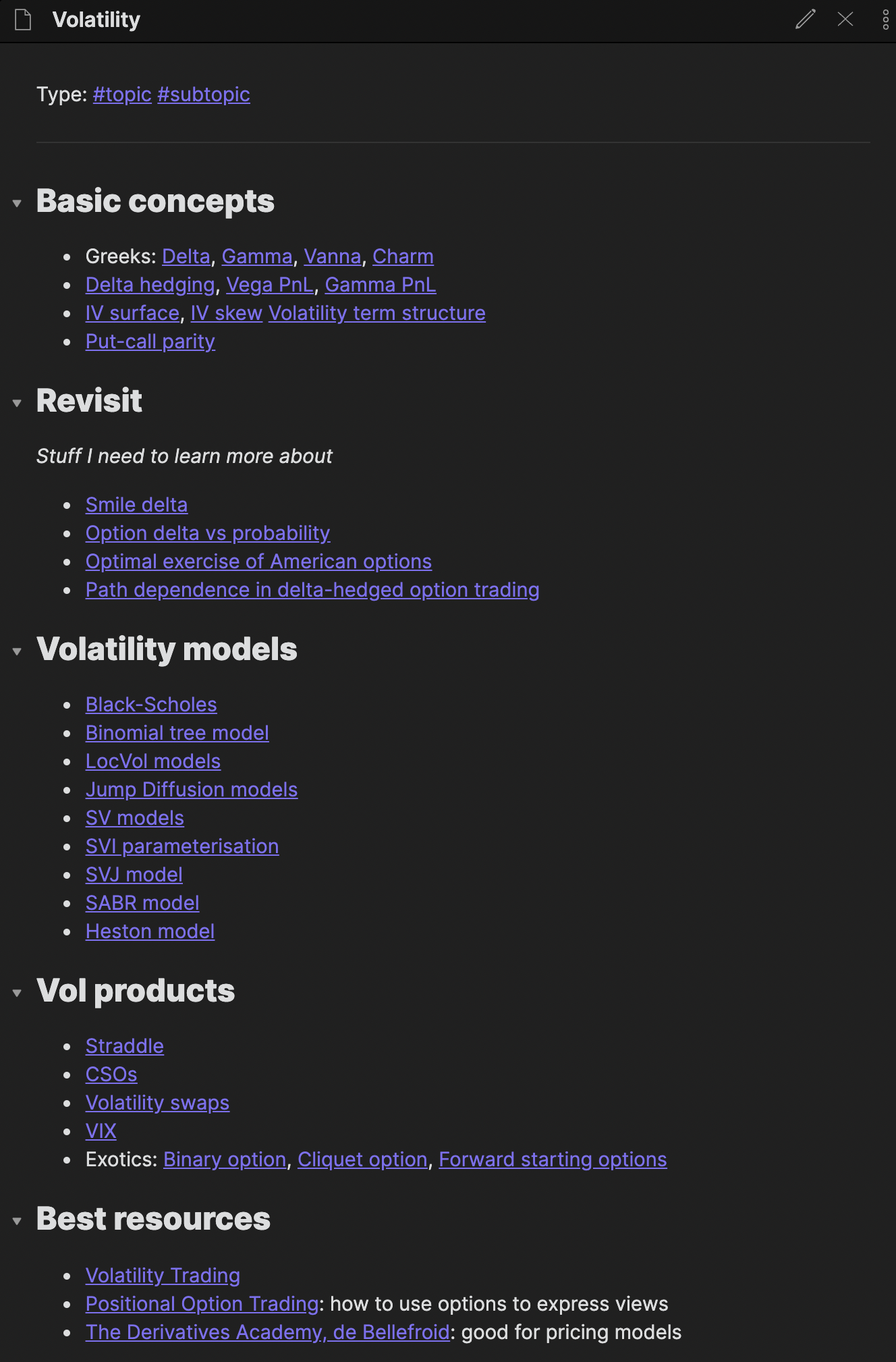
I need to eventually make MOCs for other Topics too!
Integration with PDF highlights
I’m still trying to figure out if there’s a better workflow for integrating PDF highlights with my system. This could be useful when taking notes on journal articles and textbooks.
Currently, I do all of my highlights on the first pass, then manually type notes into my Second Brain on the second pass. This has some advantages (avoiding completionism, filtering for importance) but also requires a bit more effort.
MarginNote looks promising (thanks to Lyra for the suggestion) and there are some workflows which connect Obsidian to Zotero (see this video by Artem Kirsanov).
Ongoing events
Obsidian is very well suited to creating a garden of permanent notes. But in fields like finance, one must also track ongoing events and examine how certain narratives play out over time. This is a task that traditional systems like OneNote, MS Word, or even email threads are actually quite good at because by its nature, event-tracking is more “linear” with the flow of time.
One of my exploration areas: can we design a system that combines linear event tracking with an interlinked Second Brain? I have been exploring some workflows based on Daily Notes (a popular concept in Second Brain circles), but haven’t settled on anything concrete yet. There are some tools like reflect.app which aim to solve this but I haven’t really explored them.
Molecular Notes in teams
For me, working on my Second Brain is a highly individual activity. That said, it’s natural to wonder whether Molecular Notes could be useful in group settings as an alternative to a wiki.
I think one could make this work, provided:
- The team is small: if there’s too much content it ends up being difficult to use
- Everyone is on the same page about what “deserves” to go into the collective brain
- The team puts a lot of effort into maintaining maps of content (see above) – this would be essential to allow someone to quickly review what’s in the second brain without having to wander around other peoples’ notes.
Conclusion
Having published these posts on Molecular Notes, along with my two previous posts on How I Use Notion and How I Read Books, I think I’ve said all that I want to say about productivity tools for the time being. Writing about personal productivity always feels somewhat self-indulgent; it inevitably comes down to “this is how I do things – you should do it too!”.
Thanks to Niamh Q, Callum M, Shiv G, Lyra G, Cedric C, Joseph C for the discussions and inspiration. Writing these posts has given me a great excuse to nerd out about productivity tools and human-computer interaction with you clever people!