Learning Machine Learning
Two years ago I was an absolute novice at machine learning: I had read around the subject a little bit, could probably rattle off a few of the buzzwords, and had some appreciation of the general idea, but there was no way I could have developed a predictive model beyond linear regression. I was somewhere near the peak of Mount Stupid (from a great chart by SMBC):
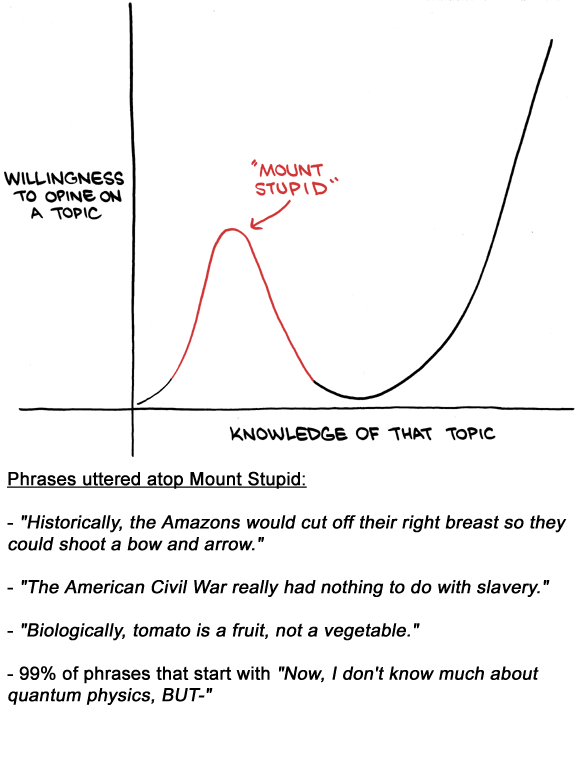
Fast forward to the present day – I’m just about escaping the local minimum on the other side. Although I definitely wouldn’t claim anything close to mastery of the subject, a few months ago I took a step back to look at my progress and realised that I was definitely not a beginner any longer: I had built a couple of extensive projects, created some educational resources, and started applying machine learning models to my professional work. I therefore think that I am in a reasonable place to share the mistakes I made when learning ML, so that other people don’t have to make them!
Edit as of Jan 2022: in retrospect, this post was probably written near the Dunning-Kruger peak. I will happily say that I am in one of the valleys, though I’m not sure which one. That said, I still stand by the advice in this post!
It is worth noting that two years is a very long time; I was far too occupied (with the army, among other things) to commit fully to machine learning, but I think that most people could achieve near-mastery in 6 months if they so pleased.
In any case, from the perspective of a fellow learner who has had a small head start, and without any guarantees of it being the most efficient way to learn the subject, I’m going to present some advice. The rough overview is as follows:
- Learn to code
- Learn the basics of ML
- Pick a subject you are interested in
- Pick an interesting algorithm, and dive deep
- Review your achievements
For each subsection, I’ll try to provide some resource recommendations, and some tips.
Learn to code
For better or worse, programming is basically a prerequisite for machine learning. It is true that there are some GUI environments, most notably Weka and the Azure ML studio, but users of these tools are definitely in the minority. Programming gives you far more control over the whole machine learning process. I know from experience that ‘control’ is often the last thing a beginner wants, because with great power comes the responsibility to actually write functional code, but it’s honestly hard to appreciate ML without programming. The one exception I would cautiously make is if you have experience with statistical analysis (e.g. in Excel), in which case Azure might not be a bad place to start.
For those new to programming, a natural question is what language to use. This is a big decision, but spending too long deciding will hold you back. I really recommend just picking python 3 and sticking with it: it has a very mature environment for machine learning, with simple syntax and an abundance of tutorials online. It has the added benefit of being a general-purpose language, so you can really do anything you want with it.
I can’t remember exactly how I learnt python (it was a long time ago): I recall it being a dark and uncomfortable time, probably because I tried to navigate my own way through. I suggest you choose one of the many tutorials available. Here are three suggestions:
- Automate the Boring Stuff with Python, by Al Sweigart. Very highly regarded, although it doesn’t directly address data science. It teaches the syntax, and just how useful python can be. Even if you know for a fact that you’re only interested in data science, the first 12 chapters are critical.
- A Byte of Python. A great online book which teachers you quite a lot of the language. I used this a lot while I was learning.
- Python course from Rice University. Comprehensive and beginner-friendly, but perhaps with an excessive focus on GUI programming.
Some tips:
- You don’t need to know all that much about writing classes in python, at least for ML. Understanding the basic language features, along with pandas dataframes, is probably sufficient.
- Please use python 3.
- I’d recommend against trying to learn about ML and learning the python language at the same time.
Learn the basics of ML
Machine learning is a very mathematical subject, and though it’s better if you can learn it rigorously (with all the maths), it’s not necessary. But be aware that you will need a firm grasp of your high school maths if you want to progress further.
One of the seemingly unanimous recommendations is Andrew Ng’s Coursera course. My honest opinion is that this is likely to put you off ML unless you are a very quick learner (and good at maths). I didn’t finish the course, and after giving up, I avoided ML for a long time. One of the problems is that he uses Octave/Matlab as a programming language, which nobody uses. That being said, the course does give amazing insight (provided you can follow the maths), and he covers many relevant algorithms. If you feel up to it, it may be worth following along with the videos but doing all of the assignments in python. Then you can compare your work with other people’s solutions on GitHub.
My personal recommendation is Georgia Tech Machine Learning. This course spends a lot more time explaining the intuition behind the algorithms before going into the maths or the code, which is invaluable as a learner.
I also bought the Udemy Machine Learning course for $10. While Udemy has a pretty bad rep nowadays, this course is actually decent: it gives you a basic understanding of a wide range of algorithms. There was a time when this lack of depth frustrated me, but looking back, I realise how useful it is to be given a practical tour across the whole ML scene. To be fair, you can probably learn this directly from the scikit-learn documentation , but it does help to have video explanations. I’ve put my code for this course onto GitHub.
Tips:
- If the maths is too hard, don’t worry about it. At this stage, it’s far more useful to understand intuitively how the algorithm works, and more importantly how to apply the algorithm in python. If you truly appreciate how useful ML can be, and become excited by it, you will be much more inclined to learn the maths.
- Ensure that you pick up the necessary skills with
numpy,pandasandsklearn. These libraries are fast, and knowing the common usage patterns will save you from reinventing the wheel. - Keep a folder with lots of different python files, each containing an example application of a particular machine learning algorithm to a dataset (dummy or real).
Pick a subject you are interested in
After acquiring the basic skills, it is critical to find a subject that you are interested in and to build a project. Machine learning is a widely applicable tool, and I’d wager that there’s an application of ML in whatever field you’re interested in.
Once you decide, it’s probably a good idea to look for a tutorial series on that particular topic. I was most interested in finance, so I followed an excellent youtube playlist from Sentdex, called Machine Learning for Investing.
At this stage, your goal is to build a fully working project, so that you come into contact with the whole machine learning stack, all the way from raw data to eventual predictions (and preferably some visualisations too). Performance isn’t the most important thing right now, though it would be nice if you can do better than random guessing :)
Tips:
- Try not to copy and paste code, at the very least type it out. You’ll learn faster this way.
- Don’t spend too long trying to figure out what project to do: indecision is the worst form of procrastination when it comes to learning new subjects. If you’re really struggling to think of something, try kaggle.com. Don’t be put off by the fact that it’s a ‘competition’ – it’s also a good place to learn, and lots of people share notebooks showing what they’ve tried. Seeing all these different approaches is useful for beginners, as you can quickly try experimenting with existing solutions to see what works and what doesn’t.
Pick an interesting algorithm, and dive deep
If you’ve followed the steps thus far, you should have a crude, but functional, project in a field that you are interested in. Now is the time to ascend to the next level, by really trying to understand what you are doing and improving your machine learning performance.
- Learn about cross validation, particularly about the very important bias-variance tradeoff. Improve your project’s methodology.
- Examine the different methods of sampling to make training, validation, and test sets.
- Explore different performance metrics, for example the ROC curve. Which one is the most relevant for your problem? Learn about what the F-score is, and why it’s commonly used instead of accuracy.
- Evaluate your feature importance, and maybe even try some feature selection/engineering.
After you’ve done all of this, it may be that your performance has actually gotten worse (for example, if you’ve changed to a more relevant metric). This was the case for me, as I changed from accuracy to precision – precision is much more pertinent to stock predictions because it’s the false positives that lose you money. But at least I had a logically sound methodology off of which to base future endeavours.
Now, you should do a quick search on Google Scholar to see what algorithms are most successful in your field. For example, if you chose to deal with computer vision, you’d find that Convolutional Neural Networks are the de facto standard. Then, really hit the books – try to understand the algorithm in detail, to the point where you could recreate it from scratch. This naturally involves a lot of maths, but hopefully at this stage you’re excited enough about ML to weather it. You may find The Elements of Statistical Learning to be useful: it is a legendary textbook that basically defines the field of machine learning. Supplement this with alternative explanations and tutorials from youtube or stackexchange, and you will be in a good place. In particular, you should look out for the actual meaning of all of the different metaparameters. This is very important, because it will guide your future search for optimal metaparameters to increase your performance.
In my case, SVMs and neural networks were common in the literature on stock prediction, but I wasn’t too keen to proceed with them. I found in a more recent study that boosted decision trees were having quite a lot of success in a number of different fields, so I was interested to see how they would do in stock prediction. I’ve written a post on my investigation into boosted trees, so that you can get an idea about how deep I went into the subject. I also found the seminal academic papers to be illuminating, but you should probably leave them for last.
Once you understand the algorithm, you should be able to go back to your original project with fresh eyes, applying your new knowledge to increase performance. But even if your performance won’t increase, you’ll have a much better idea as to why.
Review your achievements
Although it is true that there is always more to learn about a subject, sometimes you do need to take a step back and acknowledge that you’ve come a long way. Look over your projects, your notes, and take some pride in what you have learnt. I’m most proud of an extensive tutorial I made, MachineLearningStocks, which is meant to help beginners get started with applying ML to stock prediction.
Conclusion
Machine Learning is a subject that is not hard to pick up, but has a learning curve that steepens the further you get into it. Just being able to apply machine learning puts you ahead of most of the world. It is constantly evolving, with a startling amount of research released daily. But don’t let this put you off: with concerted effort and the right resources, it’s definitely feasible for you to contribute to that ever-expanding corpus.