Projects
This page describes some of the projects I’ve worked on. The projects are in approximately decreasing order of “importance” (whatever that means).
- ReasonableDeviations
- PyPortfolioOpt
- BinancePremiums
- Crypto market-making in Julia
- MLStocks
- HyperVault
- HireYou
- KindleClippings
- pValuation
ReasonableDeviations
This blog has been one of my longest-running projects! The blog runs on Jekyll (a Ruby library) and is hosted on GitHub. All the blog posts are written in markdown, which I have become very familiar with. While the posts in the site are creative-commons licensed (i.e can be used for many things with attribution), the website is open source under the permissive MIT license – though I’d be a bit miffed if someone decided to clone the site without changing the fonts or the colours!
PyPortfolioOpt
PyPortfolioOpt implements financial portfolio optimisation in python. I wrote the package because at the time the existing implementations were unintuitive and poorly documented – this project was born out of the need for a comprehensive plug-and-play portfolio optimisation library.
Relevant links:
BinancePremiums
BinancePremiums is a tool I built to track the basis between spot crypto and futures on the Binance exchange and explain how one might put on arbitrage trades.
I built the tool in python using the amazing Streamlit library, then deployed it on Heroku.
Relevant links:
Crypto market-making in Julia
Towards the end of my undergrad degree, I became very interested in the Julia programming language. With python-like syntax, ridiculous performance, and some really cool metaprogramming, it seems like a great language to use for finance.
To that end, I built a simple market-making bot in Julia. The goal was to make something extensible, such that we could swap in/out different parts of the bot (e.g. midprice estimates and volatility estimates).
The bot was nowhere close to being profitable, but it was a wonderful dev experience – Julia will now be my go-to for any performance-critical applications.
I will probably open-source this code at some point, but no promises!
MLStocks
The goal of MLStocks was to use machine learning to discover relationships between equity fundamentals and share price performance. Looking back on this project, I made every mistake in the book: overfitting, lookahead, wonky backtests. I leave it up as a historical artefact because despite all of its flaws, it was a wonderful learning experience.
I later released an open-source educational version of the project called MachineLearningStocks, which received generally positive response.
Relevant links:
- GitHub repo
- Post: DIY MachineLearningStocks
- Post: Learning Machine Learning
- Post: Automating the download of historical stock price data from yahoo finance
HyperVault
HyperVault was an enterprise blockchain startup dedicated to providing secure access control to sensitive documents. Think google drive, but for secrets. I built HyperVault with two team-mates over the course of 6 months during my first year at Cambridge. I worked on both the business (strategising, pitch decks) and tech aspects. The tech was quite interesting – we used Hyperledger Fabric for the blockchain stuff and NodeJS/expressJS/nunjucks for the web app. I spent a lot of time on the frontend, which is something I normally avoid.
All said, our functional proof-of-concept was very well received by both technologists and VCs and we won the £2000 prize at the Future of Blockchain competition.
Relevant links:
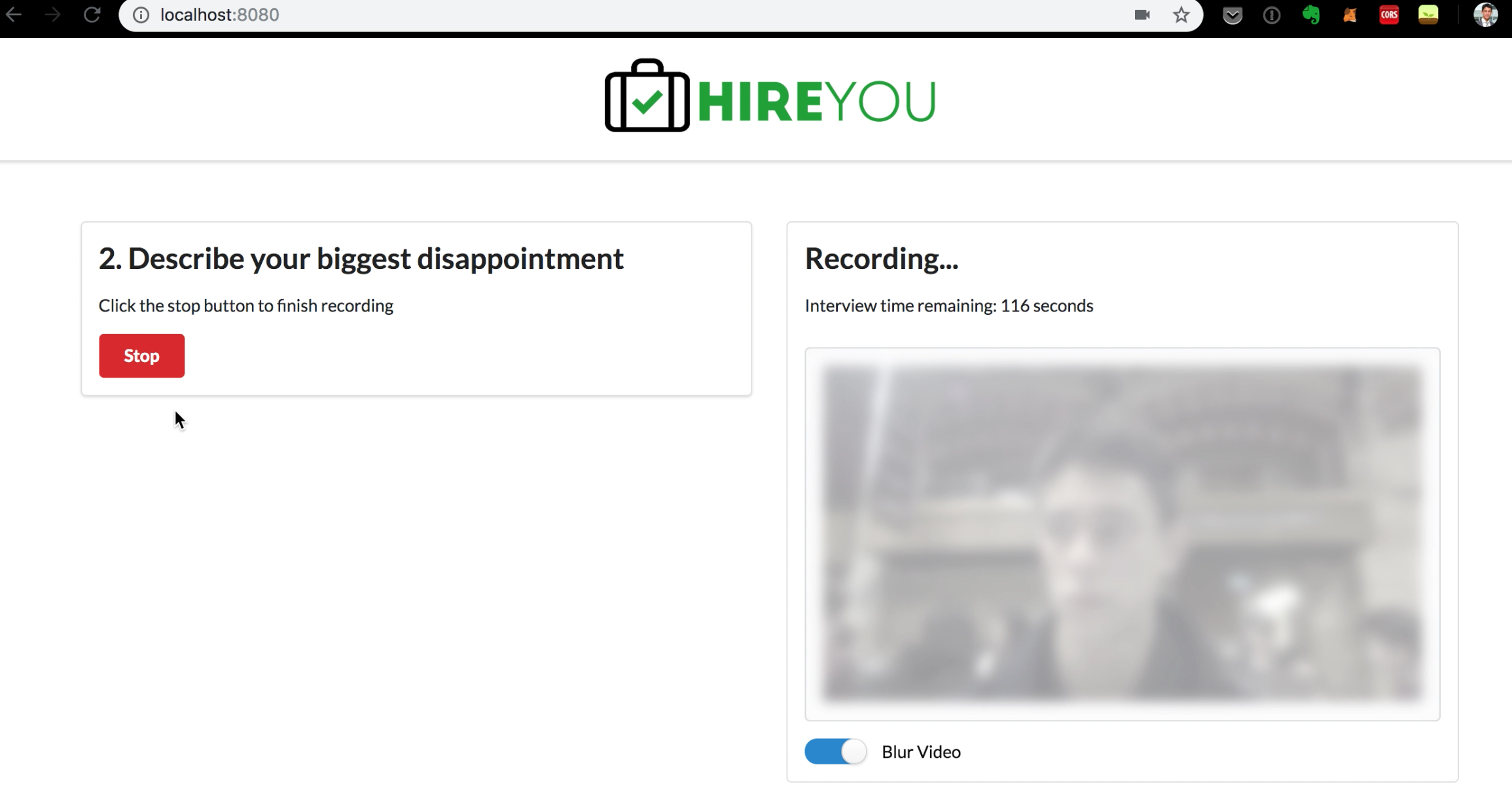
HireYou
HireYou is an interview preparation app specifically targeted at video interviews (run by vendors such as HireVue and Sonru). I have probably done 30+ interviews over the course of two years of applying for internships in financial services and I have found every single one of them to be painful. They are extremely impersonal and allegedly reject candidates for many rather arbitrary reasons, such as not making sufficiently good eye contact with the web camera when talking.
After my first round of internship applications, I realised that video interviews were a conspicuous weakness for me, so I decided to build a preparation app. Fortunately, this coincided with a hackathon, so I was able to build a proof-of-concept with the help of some friends. I then made significant modifications and deployed it live for a couple of years before eventually taking it down as I ran out of bandwidth to maintain it.
KindleClippings
KindleClippings is a small script I use to pull all the highlights from my Kindle onto my computer, rearranging them into clean text files. In addition to being a great beginner python project, this script is a critical part of my reading workflow.
Relevant links:
pValuation
pValuation is a project for which I had grand but unfulfilled ambitions. The idea was for it to be a collection of investigations into different aspects of quantamental finance (or rather, supporting code for writeups on this blog). While I had several investigations planned (technically still in the pipeline), these have been shelved for the time being. Some of the stuff that I did manage to get done: